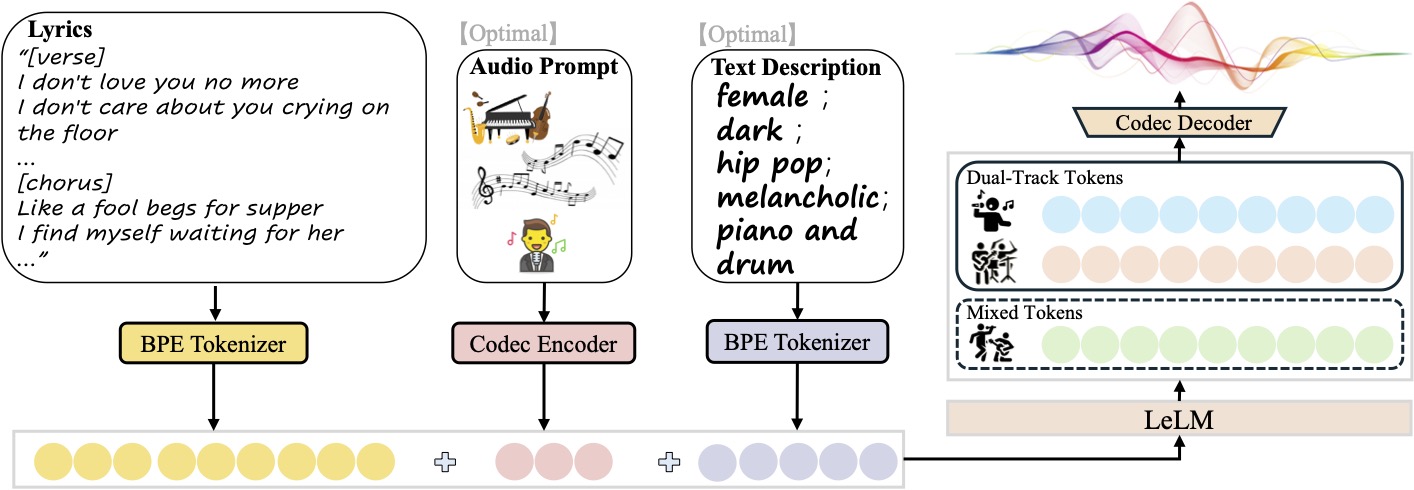
Magenta Realtime
综合介绍
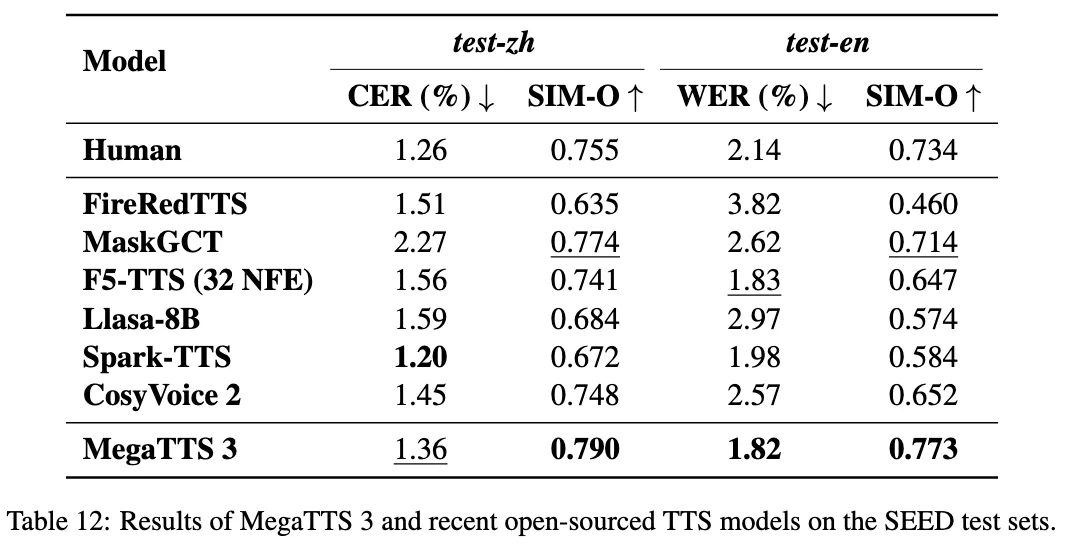
Magenta Realtime 是一个由 Google DeepMind 开发并开源的 Python 库,它为开发者和音乐人提供了一套在本地设备上进行流式音乐生成的工具。该项目是 Google MusicFX DJ 模式和 Lyria Realtime API 的开源对应版本,其核心是一个名为“Atom”的8亿参数转换器模型。 与一次性生成完整音轨的传统模型不同,Magenta Realtime 专注于实时交互,能够以极低的延迟(在免费TPU上,生成2秒音频仅需1.25秒)生成音乐,使其成为一种可以实时演奏和控制的乐器。 用户可以通过文本描述或参考音频片段来引导音乐风格,并且可以实时混合和切换这些风格。 它的实现方式是将音乐以2秒为单位分块生成,每一块都基于前10秒的音频上下文,并通过交叉淡入淡出的方式确保块之间的平滑过渡。 Magenta Realtime 的代码采用 Apache 2.0 许可证,而模型权重则在 Creative Commons 许可下提供,旨在鼓励社区在实时音乐应用领域进行探索和创新。
功能列表
- 实时流式生成: 模型以2秒的音频块为单位连续生成音乐,适用于现场表演和互动场景。
- 多模态风格控制: 支持使用文本提示(如“放克”、“重金属”)或参考音频作为风格输入。
- 风格混合: 用户可以为不同的风格(文本或音频)分配权重,实时、无缝地融合多种音乐风格。
- 低延迟性能: 经过优化,可在消费级硬件(如免费的Google Colab TPU)上实现快速推理,生成速度超过实时速度。
- 高质量音频: 底层使用 SpectroStream 编解码器,处理 48kHz 的高保真立体声音频。
- 开源模型: 提供开放的模型权重,允许开发者和研究人员进行微调、修改和构建新的应用程序。
- 上下文感知: 每次生成都会参考过去10秒的音频内容,以保持音乐的连贯性。
使用帮助
Magenta Realtime 设计的目标是成为一个实时音乐创作的伙伴。以下是如何安装和使用它的详细步骤。
环境准备与安装
最快捷的入门方式是使用官方提供的 Google Colab 笔记本,它可以在免费的TPU上实时运行,无需在本地进行复杂的配置。
对于希望在本地机器上运行的用户,需要确保你的机器拥有合适的硬件(推荐使用GPU或TPU以获得最佳体验)。
- 安装库:根据你的硬件选择不同的安装命令。打开你的终端或命令行工具,输入以下命令之一:
- GPU支持:
pip install 'git+https://github.com/magenta/magenta-realtime#egg=magenta_rt[gpu]' - TPU支持:
pip install 'git+https://github.com/magenta/magenta-realtime#egg=magenta_rt[tpu]' - 仅CPU(性能较低):
pip install 'git+https://github.com/magenta/magenta-realtime'
- GPU支持:
- 开发者安装:如果你希望修改代码或为其贡献,可以克隆仓库并在可编辑模式下安装:
git clone https://github.com/magenta/magenta-realtime.git cd magenta-realtime pip install -e .[gpu]
核心功能操作流程
1. 基本音频生成
这是最基础的用法,通过指定一种风格来生成一段固定时长的音乐。
- 步骤一:导入必要的模块首先,需要从
magenta_rt库中导入system和audio模块,并导入IPython.display以便在Jupyter环境中播放音频。from magenta_rt import audio, system from IPython.display import display, Audio - 步骤二:初始化MagentaRT系统创建一个
MagentaRT类的实例。这个对象将管理模型和生成过程。mrt = system.MagentaRT() - 步骤三:定义风格使用
system.embed_style()函数来创建一个风格嵌入。你可以输入任何文本描述,比如“funk”或“cinematic piano”。style = system.embed_style('funk') - 步骤四:循环生成音频块设置你想要的音频总时长(例如10秒)。然后,在一个循环中,反复调用
mrt.generate_chunk()。这个函数会返回更新后的状态(state)和新生成的音频块(chunk)。你需要将每次返回的状态传递给下一次调用。num_seconds = 10 chunks = [] state = None for i in range(round(num_seconds / mrt.config.chunk_length)): state, chunk = mrt.generate_chunk(state=state, style=style) chunks.append(chunk) - 步骤五:拼接并播放音频将所有生成的音频块使用
audio.concatenate()函数拼接起来。crossfade_time参数用于在块之间创建平滑的过渡效果。最后,使用display(Audio(...))来播放最终的音频。generated = audio.concatenate(chunks, crossfade_time=mrt.crossfade_length) display(Audio(generated.samples.swapaxes(0, 1), rate=mrt.sample_rate))
2. 混合文本和音频风格
Magenta Realtime 的一个强大功能是能够融合多种风格,这些风格可以来自文本,也可以来自你自己的音频文件。
- 步骤一:导入 MusicCoCa 模型除了
audio模块,还需要导入musiccoca模块,它是用于创建多模态风格嵌入的模型。from magenta_rt import audio, musiccoca import numpy as np - 步骤二:加载风格模型和参考音频初始化
MusicCoCa模型。然后,使用audio.Waveform.from_file()加载你自己的音频文件(例如一个MP3)。style_model = musiccoca.MusicCoCa() my_audio = audio.Waveform.from_file('myjam.mp3') - 步骤三:定义带权重的风格列表创建一个列表,其中每个元素都是一个元组,包含一个权重(浮点数)和一个风格(音频对象或文本字符串)。权重越大的风格在最终生成结果中的占比越高。
weighted_styles = [ (2.0, my_audio), # 参考音频的权重为2.0 (1.0, 'heavy metal'), # “重金属”风格的权重为1.0 ] - 步骤四:计算混合后的风格嵌入该库会自动处理嵌入和加权平均的过程。你只需提取权重和风格,然后让
style_model.embed()处理它们,并根据权重进行标准化和平均。weights = np.array([w for w, _ in weighted_styles]) styles = style_model.embed([s for _, s in weighted_styles]) weights_norm = weights / weights.sum() blended_style = (weights_norm[:, np.newaxis] * styles).mean(axis=0) - 步骤五:使用混合风格进行生成将上一步计算出的
blended_style传递给mrt.generate_chunk函数的style参数,后续的生成流程与基本生成相同。
应用场景
- 现场音乐表演DJ或电子音乐人可以在现场演出中实时改变音乐的风格和节奏。例如,从一个平静的氛围音乐无缝过渡到一个充满活力的鼓点节奏,或者将观众提供的音频样本实时融入到表演中。
- 创意工具与原型设计音乐制作人或游戏音效设计师可以使用此工具快速尝试不同的音乐创意。他们可以通过输入简单的文本提示(如“悲伤的大提琴”或“8-bit游戏配乐”)来快速生成音乐片段,验证其是否符合项目需求,从而大大加快创意迭代速度。
- 教育与学习音乐学生可以用它来直观地理解不同音乐流派(如爵士、古典、摇滚)的构成元素。通过混合不同的风格,他们可以探索流派融合的可能性,加深对和声、结构和节奏的理解。
- 互动艺术装置艺术家可以创建能够与环境或观众互动的声音装置。例如,一个装置可以根据房间内观众的移动或声音来改变生成的音乐风格,创造出一种动态、不断变化的沉浸式听觉体验。
QA
- Magenta Realtime 和其他AI音乐工具有什么不同?主要区别在于“实时交互性”。 像Suno或Udio这样的工具通常是“一次性”生成完整的歌曲,用户输入提示后等待结果。而Magenta Realtime被设计成一个乐器,它以极低的延迟持续生成音乐,允许用户在生成过程中通过改变提示来实时控制和塑造音乐,就像演奏乐器一样。
- 我需要什么样的硬件才能运行它?虽然它可以在仅有CPU的机器上运行,但为了获得最佳的实时体验,官方强烈推荐使用带GPU或TPU的硬件。 最简单的方式是在Google Colab上使用免费提供的TPU资源,这可以避免复杂的本地环境配置,并确保流畅运行。
- 生成的音乐可以用于商业用途吗?可以,但责任自负。该项目的代码部分使用Apache 2.0许可证,而模型权重则使用Creative Commons Attribution 4.0 International许可证。 Google声明对用户生成的输出不主张任何权利,但同时也强调,用户需要自行负责确保生成的内容不侵犯他人的版权。
- 这个模型能理解复杂的音乐理论吗?该模型通过在大量音乐数据上进行训练来学习模式、风格和结构,但它并不像人类一样“理解”音乐理论。它的一个已知局限是,在没有人类指导的情况下,可能难以维持长期的、复杂的音乐结构。 因此,它更适合作为一种创意辅助工具,而非完全自动化的作曲家。